A few months ago, I came across what looked like a real gem on eBay US: a studio copy of Intel’s iconic “Bong” sound. Yes! The famous 5-note jingle composed by Walter Werzowa in 1994 and used by Intel since the Pentium II era (starting in 1996).
According to the seller, the tape is a digital DAT (Digital Audio Tape) master from the post-production company Point.360 (still in business today), which worked with Intel in the 90s. The label on the tape had been torn, but some details are still readable: an Intel internal identification number (IIPCxxxx), along with other IDs (WO# 00123528 / GR #100).
I promptly bought it and then began the hunt for a decent DAT player locally. That stuff is still pricey! In the end, I found a refurbished Sony DTC-790 at a good price so I could test the tape. Here’s the result:
After about 20 seconds of the standard calibration tone, a female voice says: “This is for Intel Corporation. ID number IIPC5100. Audio signature ID for the Intel Inside Pentium III Processor for Worldwide use.” followed by the famous bong! What a nice treasure!
This isn’t the very first version used for the Pentium II, but the second revision used from 1999 to 2006 for the Pentium III and Pentium 4. Personally, I find this version the most iconic (the earlier one sounds much less dynamic to my ear). You can listen to all the revisions of the “bong” (there are dozens) on this website.
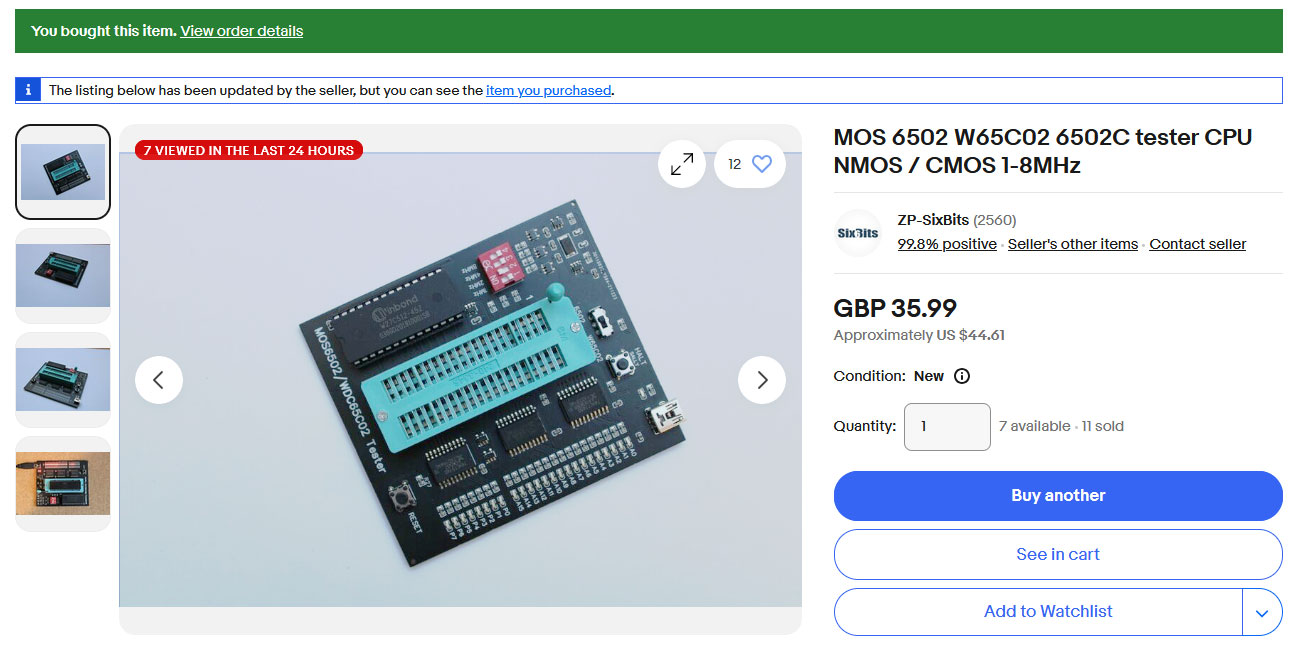
During the beta-testing phase of the Universal Chip Analyzer (UCA), some testers noticed that certain CPUs failed on the UCA while appearing to work on more basic testing devices. To determine whether this discrepancy was due to a flaw in the UCA, I purchased a couple of these simpler testers for comparison. Out of five 6502 CPUs that the UCA had flagged as defective, two passed without any issues on the basic testers. To verify their actual condition, I tested them in a real Apple IIe. Both failed to boot the system, prompting me to analyze their behavior further using a logic analyzer.
To understand why this happens, it’s important to look at how common CPU testers—readily available on eBay and other marketplaces—operate. The simplest type, known as a “NOP Tester,” provides a basic clock signal, often generated by a simple oscillator such as a NE555 timer. It permanently feeds a NOP (No Operation) instruction to the CPU’s data bus, instructing it to do nothing except cycle through all addresses indefinitely. In a 6502, the NOP instruction is represented by 0xEA (in binary: 1110 1010), which is hardwired onto the data bus. If the address bus increments smoothly and continuously, indicated by LEDs displaying changing values, the CPU is considered functional.
6502 NOP Tester from circuitsurgery.com
More advanced testers, like the ones I purchased, incorporate an EPROM containing pre-programmed test code. These devices use 74HCT245 bus transceivers to drive LEDs that display the 16-bit address bus (A0-A15) and a 74HCT574 flip-flop to control an 8-LED moving dot pattern on the data bus. The ROM feeds instructions to the CPU, allowing for slightly more complex testing than a simple NOP Tester.
6502 ROM Tester from eBay
However, despite being more sophisticated, EPROM-based testers still fall short of replicating a real computer environment. Unlike a basic tester, an actual computer relies on RAM, external peripherals, and extensive arbitration logic to manage operations. This is why CPUs have so many additional pins beyond just data and address lines. For instance, the 6502 includes bus arbitration signals like READY, IRQ, NMI, READ/WRITE, SYNC, SO, and derived clock signals Ø1 and Ø2. Most cheap testers either ignore or fail to adequately evaluate these critical signals. In contrast, the UCA is designed to comprehensively test every CPU pin, accurately simulating ROM, RAM, stack operations, interrupts, and other essential functions found in real-world systems.
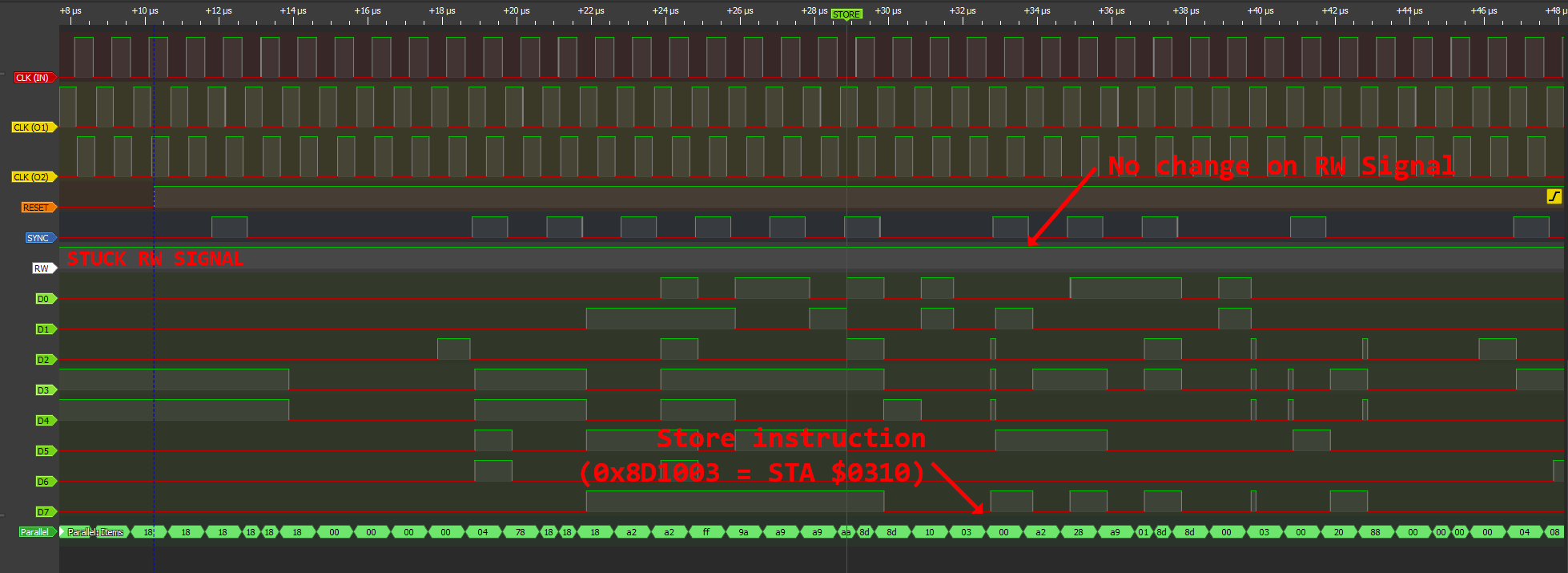
The logic analyzer helped pinpoint the exact issue: the R/W (Read/Write) pin on the two defective 6502s was stuck high (logic 1). This rendered them unusable in real computers and on the UCA, yet they still appeared functional on the basic testers.
Defective 6502 on Logic Analyzer (Click to Zoom)
This highlights the key weakness of cheap CPU testers: they only assess a limited set of CPU functions, sometimes failing to detect faults that would cause real-world failures. The UCA, by contrast, provides a much more thorough evaluation, ensuring CPUs are genuinely functional under real operating conditions rather than just passing a superficial test.
Designing a stable, adjustable and fail-safe power supply for the Universal Chip Analyzer has been one of the most challenging aspects of this project and I was quite reluctant to touch that part of the schematics. For years, the DC-DC power supply stage on the UCA Interface Board relied on Texas Instruments’ PTH08080W module, mounted upside down. While this module is excellent and performs reliably, it has two significant drawbacks.
First, it’s expensive, costing around $8–$9 per unit. Additionally, as a non-standard through-hole component, it complicates assembly and increases costs when using a reflow machine.
More importantly, the PTH08080W module needed to be replaced to implement a highly requested feature from beta testers. Previously, a 9V external power supply was mandatory in addition to the 5V provided by the USB-C to power the UCA Interface Board. That external power supply powered the DC-DC converter, which delivered an adjustable output voltage ranging from 2.8V to 5.5V at up to 2A. However, in some cases (such as testing 5V-only CPUs that consume less than 300mA), the voltage provided by USB-C alone could be strong enough. Beta testers requested an alternative power option to use only USB-C power when it’s possible, and this final revision delivers on that request.
The PTH08080W module has been replaced with a discrete DC-DC converter, complemented by additional circuitry for digital control of the voltage output. An ideal diode controller has also been integrated to manage the USB-C 5V input, ensuring seamless switching and protection in the event of a failure.
The Universal Chip Analyzer now features two automatically selected power modes:
USB-C Only (No External Power)
In this mode, the UCA can test 5V chips that draw less than 300mA. This includes, for example, all DIP40 ICs. Overcurrent and short-circuit protections are still in place, but the UCA will only allow this mode for compatible adapters. This setup is perfect for quick, portable testing in the field using a USB battery pack.
USB-C with 9V External Power
This fully featured mode supports all UCA functionalities, including the ability to test a wide range of components, from early DRAM to late 5×86 chips. Adjustable voltages (e.g., 3.3V, 3.45V) are supported, with high current capability up to 2A. This mode is ideal for advanced bench analysis and testing of more demanding components.
With this final challenge resolved, I’ll be updating the UCA website and opening preorders in two weeks.
The Universal Chip Analyzer (UCA) beta testing is entering its final phase! Thanks to the valuable feedback from talented professionals and passionate retro enthusiasts, two critical improvements were identified and addressed before the official release. The first improvement concerns the Interface Board, and a detailed update is coming soon. The second key enhancement involves the DIP40 Adapter, which initially required additional top adapters to test common CPUs like the Zilog Z80, Motorola 6800, and MOS 6502.
These extra adapters were necessary because the power and ground pin configurations of these processors differ from those of Intel’s 8085/86/88, for which the original DIP40 adapter was designed. Switching VCC and GND to other pins is technically not very complex, but it’s much more difficult to keep these pins simultaneously usable by high-frequency signals. The transistors required to switch power lines add various parasitic noise to the pins, even when they’re switched off.
I’m happy to announce that the final DIP40 Adapter is now able to test the most common DIP40 CPUs from the 70s and 80s out of the box, without the need for any additional adapters! Here is a comparison of the old DIP40 adapter with some of its various top adapters, versus the newer “all integrated” one:
The DIP40 Adapter has a 4-way dip switch to select the CPU under test between the following:
Intel 8086/8088
Intel 8085
Zilog Z80
National Semiconductor NSC800
MCS-48 (80C48)
MCS-51 (8051)
RCA CDP1802 (COSMAC)
Intel 8087 (Work in progress)
Motorola 6800
Motorola 6801
Motorola 6802
Motorola 6809
MOS 6502
MOS 6510 (or MOS6509, still TBD, would like your opinion!)
All these CPUs are now supported by the DIP40 Adapter directly! This should cover 95% of the most common CPUs that came in DIP40. What about more obscure ones? If you zoom in on the picture above, you can see that two positions of the configuration switch are marked “CUSTOM #1” and “CUSTOM #2”. Users will be able to upload any other firmware to these two slots. For example, CPUs like the Motorola 6809E or the Ricoh 2A03 can be added in the custom slots when they become available. Basically, any CPU with VCC on pins 5, 6, 7, 8, 11, and/or 40, and GND on pins 1, 20, 21, and/or 29 can be supported. Some niche CPUs like the Signetics 2650 or the Intersil 6100 (which have vastly different pinouts compared to all other CPUs) will still need a custom adapter, but the new DIP40 Adapter alone should be enough for almost everyone out of the box, from pinball enthusiasts to retro researchers.
The Universal Chip Analyzer made another step in its journey to the prehistoric age of CPUs. The Intel 8080, released in 1974, was already based on very old technologies and quite hard to interface with compared to its competitors (Zilog Z80 and Motorola 6800), but the Intel 8008 is even more archaic. Originally designed as a custom chip for a computer terminal produced by Computer Terminal Corporation (CTC), the 8008’s development was challenging due to its ambitious design requirements and the limitations of the technology at the time. Intel, which was then a fledgling company, took on the task, and with contributions from famous engineers Federico Faggin and Ted Hoff, successfully created a microprocessor that could handle an 8-bit data path. Although CTC eventually abandoned the project due to delays, the 8008 found a home in other applications. It was embraced by hobbyists and small companies, most notably being used in the French Micral N in 1973 and the Mark-8, two of the earliest personal computers. Neither of them had monitors or keyboards: input was done using switches and output was done using LEDs.
From an electrical point of view, implementing support for the 8008 on the UCA was a challenge. It doesn’t require a simple +5V referenced to ground (0V) like later CPUs such as the Motorola 6800 or the Zilog Z80 (circa 1974), nor a complex mix of +12V, +5V, and -5V (still referenced to ground) like its successor, the Intel 8080. Instead, it requires two power lines with a voltage of 14V between them. That means you can interface the 8008 using +14V and ground, or using the recommended split of +5V and -9V … without a ground reference. According to the datasheet, the +5V/-9V split should ensure compatibility with TTL logic, which is highly welcome. Like the other UCA adapters, the Intel 8008 adapter has been designed not just to test the chip but also to protect both the precious CPU and the UCA if something goes horribly wrong (like a defective chip creating a short between unexpected pins).
From an interface point of view, the 8008 was also quite challenging due to its uneven dual-clock requirement and its highly multiplexed pins (a consequence of its tiny DIP-18 package for an 8-bit CPU). Data, low address lines (A0-A8), high address lines (A9-A12 for a maximum of 16KB of RAM), and control signals are all available on the same 8 pins at different times during the internal cycle. They must be latched properly in a timely manner. But the most complicated issue to deal with was the lack of a crucial signal available on all other CPUs and MCUs: a RESET line. After power-on, the 8008 is halted, and you have to wake it up using tricky methods to make it execute code. The choice to use the instructions 0x00 and 0xFF as HALTs instead of the more common NOPs also added complexity while debugging the adapter.
Fortunately, all these challenges have been solved, and the UCA is now able to test 8008s at 500 kHz (the original frequency), 650 kHz, 800 kHz (for later 8008-1s), and a whopping 1 MHz! As with all other adapters, the UCA lets you upload your own code and run whatever program you want.
While developing the code for the UCA’s EEPROM Adapter, I came up with an idea to automatically match the contents of a newly read EEPROM to a database, allowing the user to check if the data is already known – like identifying a specific BIOS version, for instance. This would enable the UCA companion application to detect specific EEPROM contents and also verify if the data is corrupted. Additionally, users could select the brand and model of a motherboard (or any other device), choose the file revision, and automatically load the correct binary to write to an actual EEPROM. A simplified process for retro-enthusiasts.
To accomplish this, I needed a database of RAW binaries along with their corresponding checksums. The Retro Web project generously provided their BIOS databases to kick-start the project. However, many files were stored in ZIPs, RARs, ZIPs in RARs or even EXEs with multiple layers of compression. My first task was to extract all the RAW binaries, analyze their contents using tools like bios-tools and binwalk, compute their MD5 and SHA256 checksums, and organize both the raw binaries and their original files into a clear directory structure.
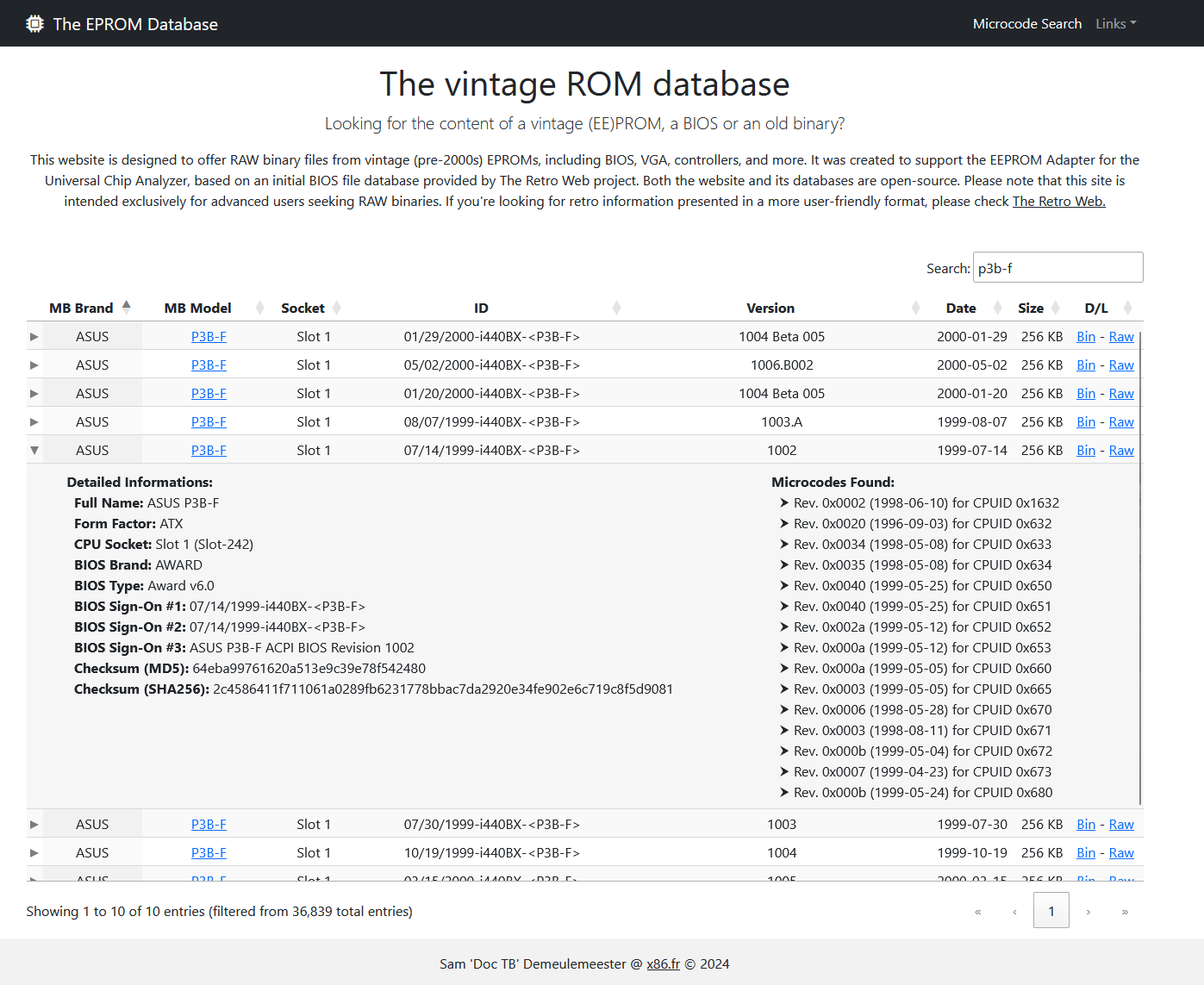
I quickly put together a basic website to showcase the database, which you can check out here: https://epromsdb.com/. It’s as simple as it gets: no fancy JavaScript, cookies, or ads. This site is intended for advanced users looking specifically for RAW binaries. For a more user-friendly experience with retro information, I recommend visiting The Retro Web.
Eventually, this content will likely be merged with The Retro Web, but for now, it’s readily available. The “Bin” option lets you download the raw binary, while the “Raw” link gives you the original package (usually with the original flashing tool) untouched. I also wrote a simple API to link EPROMSDB.com with the UCA companion app.
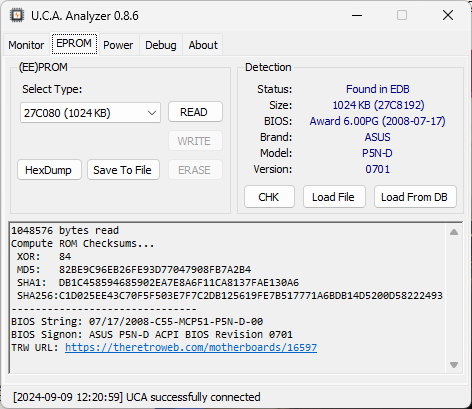
For example, here’s a 1 MB (8 Mbits) BIOS from an Asus P5N-D written to a 27C801 EEPROM, successfully read and detected by the UCA. Once the EEPROM Write code is added, you’ll also be able to select a BIOS, download the corresponding binary from epromsdb.com, and write it seamlessly using the UCA!
This project is open-source. Both the database and the file collection behind EPROMDB.com (including future updates) are available for download here: https://github.com/x86fr/epromsdb. Hopefully, this will help keep older computers running and contribute to the digital preservation of vintage hardware.
Preserving the content of ROM, EPROM, and EEPROM is crucial for maintaining and restoring vintage electronic devices like retro-computers. These memories hold critical software, firmware, or microcode to ensure device’s functionality. Over time, the data stored in these chips can degrade due to age or environmental factors like lightning condition or humidity, leading to the whole device to fail. Beyond functionality, the preservation of this data holds significant historical value. The software and firmware embedded in these chips are often unique, reflecting the technological knowledge and practices of their time. Safeguarding their data allow to maintain the historical authenticity of these devices and enable accurate emulation on modern systems.
To solve these problems, let’s introduce the EEPROM Adapter for the Universal Chip Analyzer! EEPROM reader/writer are often expensive, unreliable or complex to use with many jumpers or DIP switches. Thanks to the UCA modularity, a single adapter can support the vast majority of standard 8-bit read-only memory, including early ROM, EPROM, EEPROM, Flash, and more! As of today, it has been tested successfully in read mode with EPROM ranging from 16 Kbits (2716) to 8 Mbits (27C801) including EEPROM (28Cxxxx) and Flash (28Fxxxx & 29C/Fxxxx). The integrated voltage regulator of the UCA also allow to read modern 3.3V-only Flash chips like 29EExxxx series. 28 and 32-pin PLCCs can also be supported using cheap and widely available Socket adapters.
At this point, you might be wondering: what about writing? While reading data from these chips is relatively straightforward – simply a matter of toggling a 5V power line between the appropriate pins – writing is much more complex. Writing to (EE)PROMs requires generating and switching high voltages (ranging from 9V to 25V) across one or more “Write” pins. To address this, the UCA EEPROM adapter includes a digitally programmable DC-DC boost converter and a set of transistors to manage the high voltage switching to the necessary pins. Although the programmable converter and voltage switching have been successfully tested, the software for writing still needs to be developed. The ultimate goal is to create a jumper-free adapter capable of reading and writing to common (EE)PROMs without complicated configurations.
Another news is planned tomorrow to reveal some more details about the software behind the UCA EPROM reader.
Released in September 1989 by Intel, the legendary 486 CPU enjoyed widespread popularity in numerous PCs for many years before being gradually replaced by the Pentium and its successors. This era profoundly influenced the entire CPU industry for decades. Up until then, only Intel designed x86 microarchitectures, allowing third parties like AMD to produce Intel’s intellectual property in their own fabs. However, in the first half of the 1990s, new CPU manufacturers emerged with their own 486-compatible CPUs, designed through clean-room reverse engineering. As a result, the decade was marked by numerous lawsuits between Intel and its new competitors over patent infringements related to the x86 architecture.
By the time Intel discontinued the 486 in 2007, the definitive list of pin-compatible 486 CPU manufacturers was as follows:
Intel – The original developer of the 486, Intel released the 486, followed by the 486DX and 486SX (with a disabled FPU), then the clock-doubled DX2 and SX2, and finally the clock-tripled Intel DX4, reaching speeds of up to 100 MHz.
AMD – Biggest second source. Produced both 486-clone based on Intel’s IP and in-house tuned architecture like the AMD X5 / 5×86 up to 160 MHz.
Cyrix – Short-lived but famous company that only produced CPUs based solely on their own original designs, such as the Cx486 and the Cyrix 5×86.
ST Microelectronics – Only rebranded Cyrix CPUs
Texas Instrument – Mostly rebranded Cyrix CPUs and a custom “barely compatible” 486 core (486SXL2)
IBM – Mostly rebranded Cyrix CPUs, but also some Intel second source and even a custom 486 core internally used on IBM PCs (not on PGA)
UMC – A Taiwanese company that produced some rare 486-compatible CPUs known as “Green CPU” using their in-house low-power microarchitecture.
Although it is extremely rare to discover an unknown manufacturer of a well-known CPU like the 486, this is precisely what happened a few years ago when pictures of a peculiar and unseen 486 marked “SM486” surfaced online. Recently, I managed to acquire a couple of these elusive CPUs (a DX33 and a DX2-66). The Universal Chip Analyzer is the perfect tool for an in-depth study of these rarities. Are they merely clones of an already known 486 architecture? Are they based on a brand-new design? Where do they come from?
The story behind State Microelectronics
The first step is to identify the company behind the laser-printed logo on the CPUs. Given that they originated from China, a quick search on the Chinese internet revealed another picture of the logo with the acronym “SSMEC,” which stands for “Shenzhen State Microelectronics Co. Ltd.” This company was initially established in 1993 under the name “Shenzhen State Micro Science and Technology Co. Ltd.” It was the first IC design company to be part of China’s “909 Project,” a national initiative aimed at developing China’s semiconductor chip industry. The goal was to establish China as a competitive player in the global semiconductor industry, reduce reliance on foreign technologies, foster in-house innovation, and acquire Chinese-controlled intellectual property.
Shenzhen State Microelectronics old and new logos
After numerous reorganizations over the years, SSMEC is now part of “Guoxin Microelectronics Co. Ltd.” a subsidiary of the state-owned giant Tsinghua Unigroup. Notably, Tsinghua Unigroup also owns “Yangtze Memory Technologies Corp” (better known as YMTC), the first Chinese-owned company to design and mass-produce the critical 3D NAND Flash used in smartphones and SSDs. I couldn’t find any reference to an x86 CPU developed by SSMEC on their (very undetailed) website. It’s difficult to determine exactly what this company is currently working on. The closest reference to a potential CPU is a 2011 award given by the Shenzhen Municipal Government for a “32-bit High-performance Integrated Communication Microprocessor.”
SM486DX33 Analysis
Physically, the SM486DX33 comes in a 168-pin PGA ceramic package. The printing is rotated 90° counterclockwise, but pin 1 is marked with a small square to ensure correct orientation. There are also two numbers laser-marked on top: “035” and “1650.” The latter appears to be a date code (Year 2016, Week 50), but 2016 seems quite late for a 486 CPU. Additionally, it appears that State Microelectronics changed its logo well before 2016. A 486-class CPU should have been produced in the 1990s, unless this chip was intended for a very specialized industry, such as aerospace or military. The back of the CPU has no markings, and the gold lid is slightly different from all other known Intel 486DX CPUs.
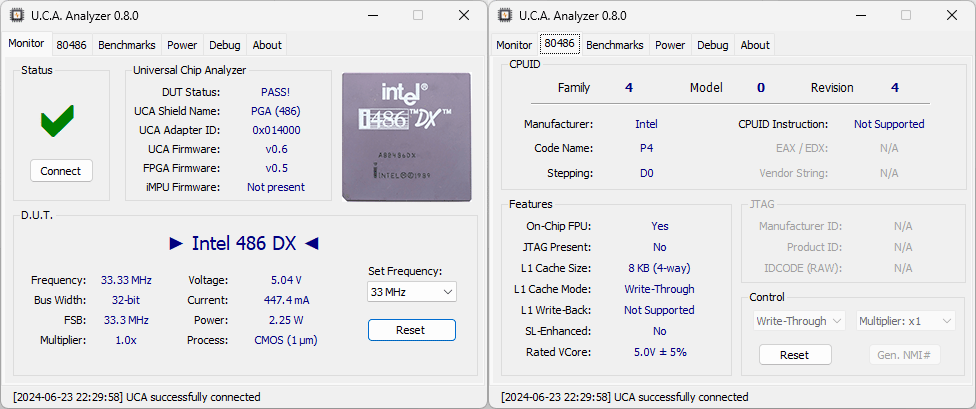
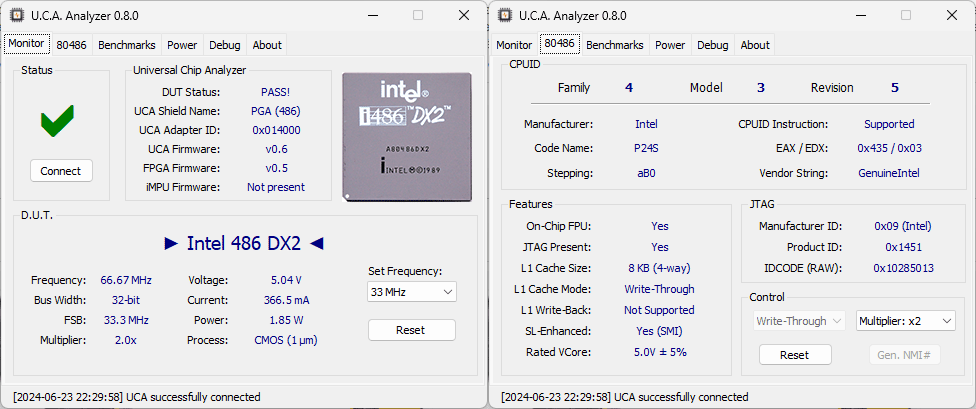
For further investigation, let’s insert the SM486DX33 into the Universal Chip Analyzer. The first step was to determine the correct voltage. At 3.45V, the SM486DX33 only booted up to 20 MHz, so 5V was clearly the correct voltage to achieve 33 MHz operation. Both benchmarks ran successfully, and the UCA concluded the test with a PASS status. Here is how it is detected:
As shown in the screenshots from the UCA, the CPU is detected as an Intel 486DX with a reset signature of 0x404. The CPUID instruction is not supported, and JTAG is not available. The 0x404 identifier matches that of an Intel 486DX with the D0 stepping (either SX419 or SX729). It is very common for other manufacturers to copy Intel’s reset signature to avoid issues with software detection. However, a look at the benchmark results leaves no room for doubt: with an INT Benchmark score of 126.5 and an FP Benchmark score of 69.4, the SM486DX33 delivers exactly the same results as an Intel 486DX-33. All the INT/FP instructions have the exact same latency and throughput, indicating that the microarchitecture of this CPU is a perfect clone of Intel’s 486.
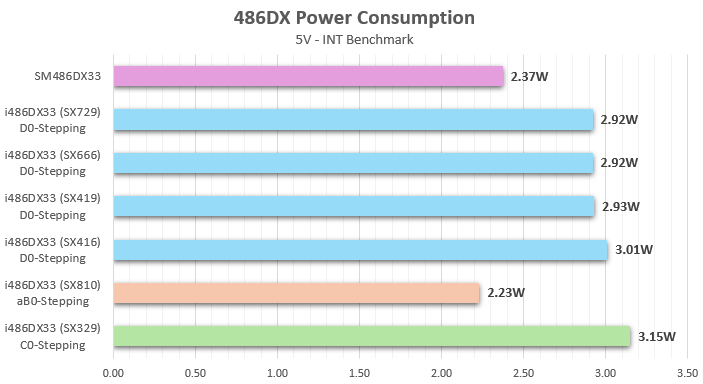
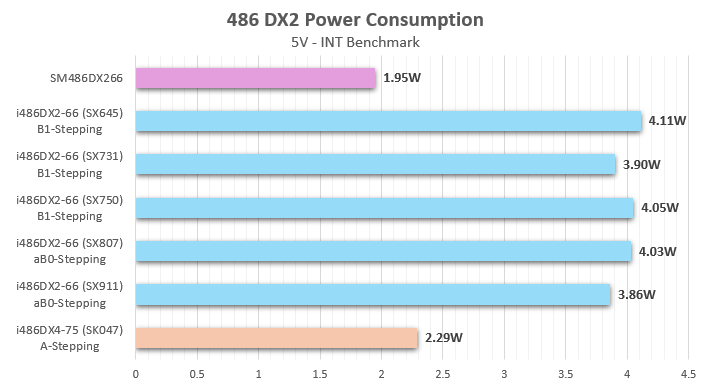
Now, we need to determine whether this SSMEC CPU is simply an Intel-produced 486 die assembled into a custom ceramic package, or if it is a clone built using a custom foundry process (possibly using Intel’s wafer masks). Again, the Universal Chip Analyzer can assist with its power-consumption profiling features. I compared the SM486DX33 with four different Intel 486DX-33 CPUs based on the D0 stepping, as well as with an earlier Intel 486DX-33 C0-Stepping and a later one built on the aB0 Stepping.
The results are quite interesting. All early Intel 486DX-33 CPUs up to the D0-Stepping are based on Intel’s P648 process (also known as CHMOS IV) with a 1 µm gate length. Later 486 models, such as the SL-enhanced SX810, use the newer P650 process (CHMOS V – 0.8 µm). At 33 MHz, the power consumption of an Intel 486DX built on a 1 µm node is 3.00 Watts +/- 5% (2.85-3.15W). Therefore, a 486 CPU returning the 0x404 (D0) signature should fall within that range. However, the SM486DX33 has a power consumption of 2.37W, which does not align with a 1 µm process, despite its signature. This suggests that the chip is built on a 0.8 µm process like the SX810, which has a 0x415 reset signature and supports CPUID and JTAG.
SM486DX266 Analysis
Now let’s examine the clock-doubled 486DX2 at 66 MHz from SSMEC. The top markings are similar to those on the SM486DX33, with two numbers: “173” and “1425.” As before, this appears to be a date code (Year 2014, Week 25) but could be misleading for the reasons previously mentioned. There are still no markings on the bottom, but the lid is much smaller, resembling the one found on later Intel 486DX4 models.
The SM486DX266 also operates only at 5V to achieve its rated speed. The UCA was able to test it perfectly. Here is how it is detected:
This time, the CPU from State Microelectronics is detected as an Intel 486DX2-66 (aB0-Stepping) with the 0x435 reset identifier, matching Intel’s specification. More interestingly, the CPUID instruction is now supported, confirming the 0x435 identifier. The CPUID Vendor String is “GenuineIntel,” just like on Intel’s 486 DX2. JTAG is also supported and returns Intel’s Manufacturer ID and the same Product ID code as the original DX2s. With an INT Score of 218.0 and an FP Score of 135.4, the SM486DX266 achieves the exact same results as an Intel 486DX2-66, indicating they share the same microarchitecture. Now it’s time to compare the power profile of the State Micro 486DX2 with Intel’s DX2.
The results are surprising once again. The SM486DX266 requires half the power of any Intel 486DX2 based on the aB0-Stepping (SX807 and SX911). Intel’s aB0-Stepping (ID 0x435) is built on the P650 process (CHMOS V – 0.8 µm). However, the power consumption of the SSMEC CPU suggests it matches a more advanced process, such as the Intel P652 (0.6 µm) process used in later 486DX4 models. At 75 MHz, an Intel 486DX4 (0.6 µm) requires about 2.3W. When clocked down to 66 MHz, this almost perfectly matches the 1.95W of the SM486DX266. No genuine Intel DX2 CPUs have ever used a process more advanced than P648 (0.8 µm), making this finding quite interesting.
Conclusion
From a microarchitectural perspective, State Micro’s SM486s are clearly an exact replica of Intel’s 486 CPUs. The latency and throughput of instructions are identical between both CPUs. Even the JTAG identifier, which is the only way to distinguish between an Intel 486 and a third-party CPU like AMD using Intel’s masks, points to Intel. It remains unclear how State Micro obtained Intel’s 486 IPs and whether they had the legal rights to use them. Intel’s licensing of x86 products, especially during the 486 era, was extremely restricted. Only AMD and IBM had the legal right to produce 486s based on Intel’s IP, and that was granted after a long legal battle for AMD. It is highly unlikely that Intel would have granted such deep cloning rights to a state-owned company in China. Even if that were the case, they would likely have changed at least the JTAG identifier.
From a process standpoint, these SM486 CPUs reveal unexpected secrets. Both appear to be a node ahead of Intel’s genuine 486s (die-shrink), suggesting they likely did not come from an Intel fab. While the Intel 486DX-33 with D0-Stepping were built on a 1 µm process, the clone from State Micro seems to use a 0.8 µm (made-in-China) process. The same applies to the SM486DX2, which seems to be based on a 0.6 µm process, whereas Intel DX2s with aB0-Stepping were only based on the 0.8 µm process.
It’s possible that these CPUs were designed as test ICs to help establish a new Chinese foundry, which might explain their rarity and why they only surfaced in 2024. Another intriguing possibility is that they were produced to ensure long-term support for critical systems designed in the 90s, such as military applications, energy infrastructures (like nuclear or oil), or heavy civil technologies. For instance, many trains in France still use AMD 486DE2 processors as on-board computers.
CPU collectors have observed a high demand for aftermarket microprocessors from the 80s and 90s from Chinese buyers since 2010. The most sought-after CPUs include the 80C186 and the 486DX33 and DX2-66 models. CPUShack, one of the largest resellers in the USA, who shipped over 1000 of these 486s to China, noted that the SX419 & SX729 (for DX33s) and SX807 & SX911 (for DX2-66s) were by far the most popular among Chinese buyers. These specific models correspond exactly to the D0 and aB0 steppings that the SM486 CPUs replicate. The exact applications of these 486s in China remain a mystery, but it’s clear that there is a significant and ongoing demand for them.
If you have any additional information about these chips, please contact me or leave a comment below – I’d love to hear from you!
A benchmark feature was planned very early in the development process of the Universal Chip Analyzer. Given the vast differences in microarchitecture between a 486 and an 8080, two benchmarks are necessary: one to compare older 8-bit CPUs from various manufacturers with incompatible instruction sets (Motorola 6800, Intel 8080, MOS 6502, etc.), and another for 16- and 32-bit CPUs based on Intel’s x86 ISA. Let’s begin with building an Integer/FP benchmark for “modern” CPUs like the 386 or 486. (I’ll cover how to evaluate older CPUs’ performance in a later post.)
So, what is a CPU benchmark? Essentially, it’s a score derived from the ratio between a piece of code designed to emulate real-world programs (using similar sets of instructions) and the time required to execute that code. While there is no debate about how to measure time, there are endless discussions about the best instructions to use for an effective benchmark. By profiling various common programs, benchmark writers determine how instructions are statistically used and then create synthetic code that mimics a similar instruction distribution.
Let’s see if and how this approach can apply to the UCA.
INT Performance Benchmark
In the 80s and 90s, the industry-standard for measuring integer performance was the “Dhrystone” benchmark, originally published in 1984 in Ada by Reinhold P. Weicker and later ported to C by Rick Richardson. Dhrystone was designed to evaluate overall system performance with a focus on integer operations, as floating-point instructions were rare at that time. The real-world programs used by Weicker to define the instruction distribution for Dhrystone were written in Fortran, Pascal, and long-obsolete languages like ALGOL. A complete description of the instruction statistics behind the C version of Dhrystone can be found in the dhry.h header file.
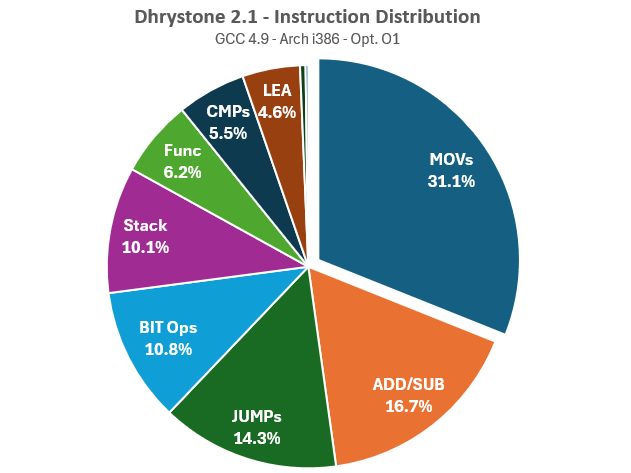
To implement a similar code in the Universal Chip Analyzer, I first needed to understand exactly what Dhrystone does. I began by compiling the original C code using GCC 4.9, targeting the “i386” architecture with the “-O1” optimization flag to avoid extreme optimization. Then, I used Intel’s Pin Architecture Analysis tool to log every instruction executed by the Dhrystone binary and sorted them. Finally, I grouped the instructions by family.
Key findings include:
MOV Instructions: About 30% of executed instructions are MOVs. Of these, 68.8% are used to read memory, 22.7% to write to memory (the usual 2:1 ratio), and 8.5% involve registers only.
Integer Operations: Integer ADDs account for 13.7% of total instructions executed, while Integer SUBs account for 3.1%.
Bit Operations: Bit operations (Boolean manipulation, shift, rotate, etc.) account for approximately 11% of total instructions, and bit-based comparisons account for 5.5%.
String Operations: About 20% of MOVs instructions are related to string operation (like movsd)
LEA Instructions: LEA instructions, a compiler trick to optimize basic arithmetic operations using a memory computation-related instruction, remain below 5%.
Program Flow Control: JUMPs are mainly conditional, with 70% being jnz (Jump if not zero). Stack operations (push/pop) and function control (call/ret) account for 16.3% of the total instructions.
As an arithmetic benchmark, Dhrystone also performs some multiplication (0.2% of the total) and division (also 0.2%). While this 0.4% may seem insignificant compared to the 16.7% for addition and subtraction, it’s important to understand that ADD and SUB instructions require only 2 cycles on an i486, while IDIV and IMULT instructions can require up to 43 cycles, making them 20 times slower. Consequently, these 0.4% of div/mult operations take as much time as 50% of all add/sub operations. This must be considered to avoid an issue where a single time-consuming instruction skews the final score.
Another crucial point is related to the memory access subsystem (including the cache, when available). A benchmark like Dhrystone doesn’t solely evaluate CPU performance, but rather how the CPU and memory perform together. To what extent? The instruction statistics show that approximately 30% of executed instructions reference a memory location, resulting in a read/write operation. With the slow memory used in the 1980s and 1990s, the final score could be directly linked to the performance of the memory (or the memory controller, or the internal cache). Should this be simulated by the UCA, given that the memory simulated by the UCA is extremely fast with zero wait state? I don’t think so. The goal here is to design a pure CPU benchmark, as independent of memory subsystem speed as possible. Nonetheless, some memory operations are still necessary to consider the latency and bandwidth of very common instructions referencing memory like MOVs.
With these results in mind, and taking into consideration the number of cycles required for instructions on CPUs ranging from the 8086 to the 80486, here is the instruction dispatch I selected for the Integer benchmark of the Universal Chip Analyzer:
5% MULT + 0.25% DIV: Same execution time than the 24% ADD/SUB
12% Boolean operation: AND, OR, XOR, INC, DEC, …
6% Rotation/Shift: ROR, ROL, SHL, SHR, …
10% conditional JUMPs: JNZ, JZ, JNE, JE, …
~20% for Flow control and stack management: PUSH, POP, CALL, RET, …
Of course, this code can be changed easily at any time to fit specific benchmarking needs.
FP Performance Benchmark
When considering floating-point benchmarks, the two clear choices were Whetstone and Linpack. I profiled both using various tools. Let’s begin with Linpack to understand why I ultimately preferred Whetstone.
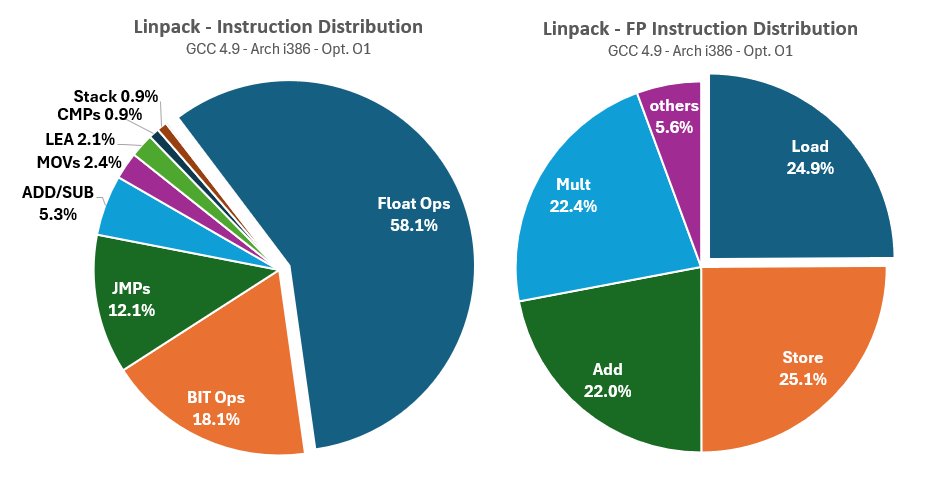
As shown in the instruction statistics charts, the authors of Linpack recognized early on that the FMA (Floating-point Multiply-Add) would become the cornerstone of intensive compute activities for decades to come. Consequently, they fine-tuned Linpack to focus almost exclusively on FMA operations.
Linpack exhibits very few memory dependencies (less than 3%) and even fewer control flow and stack instructions (less than 2%), which could be great for the UCA. However, the floating-point instruction dispatch reveals that only four FP instructions are predominantly used: FADD, FMULT, and FLD/FSTP for loading static values and storing results in registers. Linpack essentially measures the FMA performance of an FP execution unit, which is insufficient for properly evaluating an entire FPU.
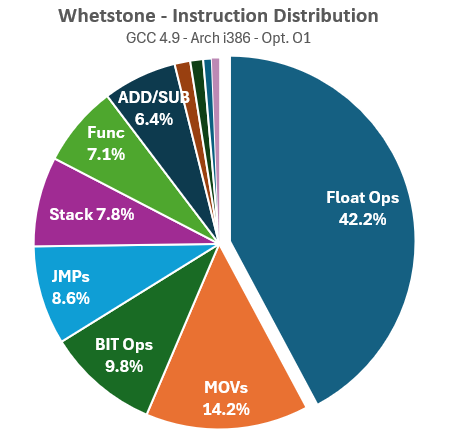
Now let’s profile Whetstone the same way, stating with all-instructions statistics:
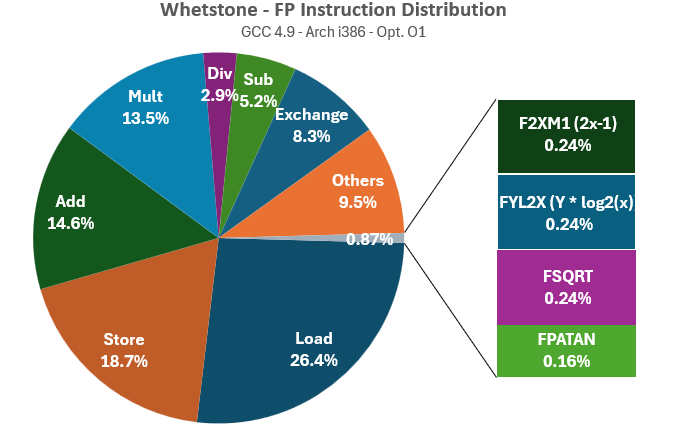
Whetstone demonstrates a more balanced use of non-FP instructions, though this comes at the expense of a lower volume of FP instructions overall. Memory dependencies, stack usage, and function control are significantly higher compared to Linpack. Next, let’s examine the distribution of FP instructions:
Whetstone utilizes the complete set of instructions available on early x87 FPUs, maintaining a balance between very fast instructions like FADD and much slower functions like FSQRT (square root), as well as even more time-consuming logarithmic, exponential, or trigonometric instructions like FPATAN, FSIN, or FCOS (which can take hundreds of cycles on any 386 or 486!). This comprehensive range is exactly what we need for a thorough evaluation of FPU performance.
To summarize, for the Universal Chip Analyzer FP benchmark, we need the non-FP instruction dispatch statistics of Linpack (with very few memory dependencies and minimal stack/program control flow instructions) combined with the variety of FP operations found in Whetstone (not just FMA but the full suite of FP operations, from square roots to trigonometric functions). Of course, we must balance these instructions to ensure no single operation disproportionately affects the overall performance.
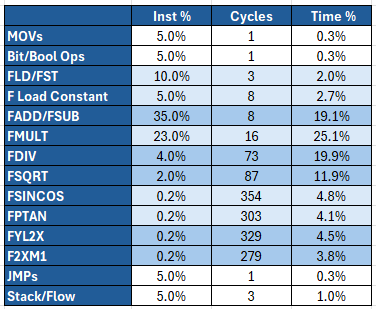
Here is my proposed dispatch that will be implemented as “V1” of the UCA FP Benchmark:
FMAs account for 45% of the total execution time, FDIV/FSQRT for 30% and log/exp/trigonometric functions for 17%. Memory dependencies are reduced to the bare minimum, as well as others program control flow instructions including stack operations.
If you’ve been following my blog since the inception of the Universal Chip Analyzer (UCA) journey, you might recall a post with the same title I published in mid-2021. At that time, I was excited to unveil the second version of the UCA, a project I had been dedicated to since 2017. Unfortunately, shortly after this announcement, the integrated circuit (IC) industry faced a significant global shortage. This crisis led to exorbitant price hikes, severely impacting the production of the UCA’s initial batch. In 2022, I made a pivotal decision to entirely overhaul the UCA project, encompassing both its hardware and software components.
Initially, I questioned the necessity of upgrading beyond the original components, a Xilinx Spartan-6 FPGA and a Cortex-M0 based microcontroller (MCU). These components seemed adequate for the previously stated applications. However, I’ve come to realize the immense benefits of this upgrade. The rationale behind the UCA’s redesign is twofold: versatility and longevity. By incorporating more powerful components, the UCA’s capabilities have been greatly enhanced, truly living up to its “Universal” moniker. This complete modular redesign not only broadens its applications in retro-computing beyond mere component testing but also incorporates every feature I envisioned without the constraints of the original Mojo development platform.
This latest iteration, internally referred to as “v3,” marks a significant evolution from its predecessors. The UCA v1 was a modification of the Mojo v3 from Alchitry, featuring custom firmware and an upgraded Flash chip. The UCA v2 introduced a superior Cortex-M0 based MCU while maintaining the core architecture of the Xilinx Spartan-6 FPGA. Below is an image showing the progression from v1 (right) to v2 (middle), leading up to the latest v3 (left):
UCA v3 Hardware
Let’s delve into the specifics of the final version of the Universal Chip Analyzer (UCA).
FPGA Upgrade – The most notable enhancement in the UCA v3 is the transition from a Spartan-6 to an Artix-7 FPGA. The original Spartan-6 XC6SXL9, a 45nm FPGA, featured 9,152 logic cells and 576 Kb of Block RAM. In stark contrast, the Artix-7 XC7A35T, fabricated on a more advanced 25nm process, boasts 33,280 logic cells and 1.8 Mbit of Block RAM. This represents a threefold increase in size, coupled with improved power efficiency and additional features like an integrated ADC. Despite being available only in BGA packaging, soldering the Artix-7 proved to be surprisingly manageable.
Microcontroller Unit (MCU) – The MCU plays a crucial role in the UCA, responsible for loading the appropriate FPGA firmware, facilitating communication between the FPGA and external devices via USB, managing integrated voltage regulators and their safety protocols, displaying information on the OLED screen, and handling various auxiliary tasks. The MicroMod Teensy, a collaboration between Sparkfun and PCJR, was selected for its ease of use, impressive power, and open-source status. Based on the NXP i.MX RT1062 microcontroller (ARM Cortex-M7 @ 600 MHz), it includes 1024K RAM, 16MB Flash, and supports an extensive range of peripherals. Its integration into the MicroMod ecosystem means it’s housed on a small, replaceable board with a standard pinout and a common M.2 connector. This not only simplifies the design but also reduces costs and facilitates future upgrades if needed.
MicroSD Card Integration – The UCA operates on various FPGA configuration files, known as bitfiles, with each hardware configuration requiring a specific bitfile. Earlier versions used a 256 Mbit (64 MB) SPI Flash IC, limiting the storage to about 100 configurations. To accommodate the larger bitfiles required by the Artix-7 FPGA, which are over 2 MB, a MicroSD card was introduced. This solution offers practically unlimited storage and, thanks to the performance capabilities of the new MCU, enables quick firmware loading – a 2.2 MB firmware can be loaded in just 500 ms.
USB-C Connectivity – First introduced in the UCA v2, the USB-C connector continues to facilitate communication with the companion app for advanced testing and monitoring. The enhanced NXP i.MX RT1062 MCU paves the way for future feature expansions.
DC connector – The inclusion of a standard 2.1mm low profile DC connector is essential for powering the adjustable DC-DC voltage regulator on the Interface (IF) board with a 9V to 12V power source. This is particularly crucial for powering newer CPUs like the 486 DX2/DX4. Two versions of the IF board are planned: a fully-featured variant supporting a wide range of voltages and a simplified version for testing 5V ICs without the need for external DC power.
Enhanced Power Regulators – The shift to the Artix-7 FPGA necessitated a complete overhaul of the UCA’s power management system, given its more complex power requirements compared to the Spartan-6. The board now incorporates two DC-DC switching regulators (one for the main 1.0V FPGA core voltage and another for the 3.3V MCU) and two linear converters (one for the 1.8V FPGA auxiliary voltage, and another as a low-noise converter for 3.3V I/O).
Despite these significant upgrades, the UCA retains its compact dimensions (85×63 mm), similar to a credit card, and continues to be based on a mezzanine stack design. The first layer is the FPGA board (as described), followed by the Interface (IF) Board, which integrates the OLED display, DUT (Device Under Test) power management, and signal conversion. The final layer is the Adapter Board, equipped with a socket suitable for a specific type of chip (CPU, DRAM, etc.).
Here’s a glimpse of the complete UCA v3 with the DIP40 Adapter Board:
UCA v3 Software
From a software perspective, the transition from the Spartan-6 to the Artix-7 FPGA in the UCA v3 brings substantial advantages. Let’s delve into some of the key developments in the FPGA domain. Xilinx, now part of AMD, recently extended the lifespan of the Spartan-6 series to at least 2030. This sounds promising, but there’s a significant caveat: Xilinx discontinued their 6-Series FPGA toolchain and development tools, known as Xilinx ISE, back in … 2013! As a result, anyone looking to code for a Xilinx 6-Series FPGA today is forced to use an outdated, bug-ridden tool that lacks support for modern operating systems like Windows 10. The only viable workaround is running the tool on an old Linux VM. To put it bluntly, working with ISE in 2024 is a nightmare.
The shift to a 7-Series FPGA like the Artix-7, on the other hand, enables the use of Xilinx’s current “Vivado” toolchain, which is under active maintenance. This change is significant. When I initially embarked on the UCA project in 2018, the learning curve was steep, and I relied heavily on Xilinx 6-Series specific primitives and IPs for simplicity. With the move to the Artix-7, I made a strategic decision to rewrite everything in pure (System)Verilog, minimizing the use of specific IPs. This approach not only facilitates future transitions to different FPGA brands or models if necessary, but it also allows for the release of all the code as open-source software.
What’s Next?
The immediate objective is to finalize the UCA v3 hardware validation as quickly as possible. My aim is to ensure the FPGA and IF boards won’t require further modifications for years, allowing me to concentrate on software development, adapter creation, and other innovative features. The initial focus will be on beta testing the DIP40 and 486 adapters. If the UCA v3 successfully runs a 486 DX4 and an 8080, like the UCA v2, I’m confident that the hardware will be robust enough for any CPU released in the 70s, 80s, and up to the mid-90s.
The Universal Chip Analyzer v3 will be available for sale soon, starting with the DIP40 adapter. Subsequent adapters will then be released one-by-one. Pricing details will be announced in the near future. While I’m considering another Kickstarter campaign, akin to my experience with the ATX2AT Smart Converter, I’m mindful of the significant time investment such crowdfunding efforts entail.
Stay tuned for more updates on the UCA, and feel free to share your thoughts and comments!